| - 目录 | |
|---|---|
| HashMap | HashMap 原理 |
| HashMap 源码 | |
注:本文源码版本均为:JDK 8
一. 原理
(1)HashMap怎么存取
%%{
init: {
'themeVariables': {
'fontSize': '13px'
}
}
}%%
graph TD
T(("HashMap
怎么存取值")):::p
T --> |"数据以键值对形式存储"| A["key — value"]
A --> |"包装为Node数组对象"| B["Node { key, value }"]
B --> |"通过node数组下标保存对应数据"| C["node[0] = new Node { key, value }
node[1] = new Node { key, value }
node[2] = new Node { key, value }
..."]
C -.-> |"[ 保存 ]
遍历数组,对应key和value"| D["for (Node node : nodes)"]
C --> |"[ 获取 ]
通过 数组索引 获取(key的hash值)"|E["node[ hash(key) ] = value"]:::lb
classDef p fill:#ddaebd
style E fill:#d9dfeb, stroke:#657eae,stroke-width:2px,stroke-dasharray: 3 3
- 使用Node数组保存、通过Node数组索引获取。
(2)Hash算法怎么写
%%{
init: {
'themeVariables': {
'fontSize': '13px',
'clusterBorder': 'none',
'clusterBkg': '#f0f2f7'
}
}
}%%
graph TD
T(("Hash算法
怎么写?")):::p
T --> |"如何计算出数组索引?hash(key)"| A["* 因为Node数组有固定的初始化默认长度(length)
* 索引值需限定在数组长度范围内(0~length-1)
* 索引值还要尽可能平衡、分布均匀"]
A --> B(["取模运算:hash % length"])
B ==> |"(更好的方案:
使用位运算效率更高)"| C(["位运算:hash & (length - 1)"])
C -.- c("length必须是2的n次幂"):::b
subgraph "前置条件"
c -.- c2["假如 key = 20, length = 16, hash & (length-1):
0001 0100 // 20
0000 1111 // 15
0000 0100 // =4"]:::c2
end
classDef p fill:#ddaebd
classDef b fill:#d2d9e7, stroke-width: 0px
style c2 color: #86868b, fill:#ebedf3, stroke-dasharray: 3 3
%% 取模运算
style B fill: #f4e4e9
%% "位运算"
style C fill:#b8c3d9, stroke:#657eae,stroke-width:2px
为了解决取模的效率问题,采用了位运算的方法:
index = hash值 & (length -1)
此时需要一个前置条件:length的长度必须是2的n次幂。
当length的长度是时,有以下公式成立: num% = num&(-1) 。🦋 因为就像十进制取余数一样,若除以10或10的整次幂数,余数刚好是取低位上的数字。同理,二进制取余数只要除以2的n次幂数,低位上的数字就是我们需要的余数。而( - 1)的二进制有效位都是1,和n位的1作与运算相当于取低n位的值。
length的长度刚好是2的n次幂,扩容也是按原来的2倍容量进行扩容,可以加快hash计算、减少hash冲突。
🦋 加快hash计算:
- 两倍扩容机制使容量一直保持在2的n次幂数,就可以使用位运算代替取模运算,提升hash计算效率。
- 当容量保持为2的n次幂时,每次扩容时位运算计算得出的余数不变,数据存放的索引位置也保持不变。而使用%计算时,结果会因为容量的变化而改变(模运算会产生小数点),每次扩容时数据在数组中存放的位置会发生改变(数据漂移),影响性能。
🦋 减少hash冲突:
- 将容量保持为偶数进行hash计算时,经过(length-1)后,计算出的索引值为奇数和偶数的概率相同(取决于随机生成的hash值);
- 而使用奇数容量进行hash计算时,经过(length-1)后,最终结果均为偶数,这样任何 hash 值都只会被散列到数组的偶数下标位置上,这浪费了近一半的空间。
- 因此2的n次幂容量、双倍扩容机制可以使容量保持在偶数值,可以使添加的元素在HashMap的数组中均匀分布,减少hash碰撞。
(3)Hash冲突怎么办
%%{
init: {
'themeVariables': {
'fontSize': '13px'
%%'edgeLabelBackground': '#ddebe6'
}
}
}%%
graph TD
T(("1. Hash冲突
怎么优化")):::p
--> T1("hash表里可以存储元素的位置
被称为“桶(bucket)”")
T1 --> |"通常情况"| A("单个“桶”里存储一个元素,
此时性能最佳"):::g
A -.-> |"O(1)"| a["hash算法可以根据hashCode值
计算出“桶”的存储位置,
接着从“桶”中取出元素。"]
T1 --> |"哈希冲突的情况"| B("单个桶会存储多个元素(hash值相同)"):::g
B -.-> |"O(n)"|b(["多个元素以 链表 形式存储
"]):::B
b --> 2T(("2. Hash冲突
很大怎么优化")):::p
subgraph "(链表必须按顺序搜索,存取性能差)"
2T --> C(["将链表结构转为红黑树"]):::B
C -.- |"O(logn)"|c["以树的高度为最差查询性能,永远不会出现O(n)的情况。"]:::info
end
classDef p fill:#ddaebd
classDef g fill:#f4e4e9
classDef B fill:#d9dfeb, stroke:#657eae,stroke-width:2px
classDef info fill:#f6f6f7,color:#737379, stroke-width: 2px, stroke-dasharray: 3 3
Hash冲突示意图
%%{ init: { 'themeVariables': { 'clusterBorder': 'none', 'clusterBkg': '#ececee' } } }%% %% 链表超过8时树化成红黑树 graph TD subgraph "Node[]" Entry0["Node0
Node<K,V>"] -.- Node1 -.- Node2 -.- Node3 -.- Node4 -.- Node5 -.- Node6 end subgraph 链表 Node1 --> A[Node] --> B[Node] --> C[Node] --> D[Node] --> E[Node] --> F[Node] end subgraph 红黑树 Node4 --> a[Node] a[Node] --> b[Node] b --> b1[Node] b --> b2[Node] a --> c[Node] c --> c1[Node] c --> c2[Node] b1 --> d[Node] b1 --> d2[Node] end style 链表 fill:#ddebe6 style 红黑树 fill:#f4e4e9
(4)内存结构示意图
创建对象,内存结构示意图:
Map<String, Integer> countMap = new HashMap<>();
countMap.put("hello", 1);
countMap.put("world", 3);
countMap.put("position", 4);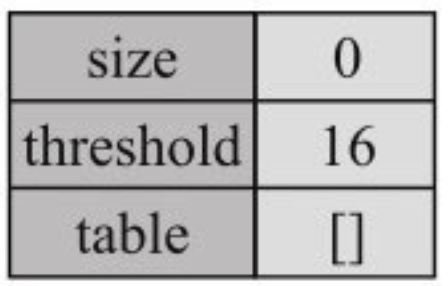
保存键值对
“hello”的hash值为96207088,模16的结果为0,所以插入table[0]指向的链表头部,内存结构变为:

“world”的hash值为111207038,模16结果为14,所以保存完“world”后,内存结构:

“position”的hash值为771782464,模16结果也为0, table[0]已经有节点了,新节点会插到链表头部,内存结构变为如图:

二. 使用
(1)常用方法
|
(2)如何遍历
graph LR
T(("遍历HashMap
的5种方法")):::p
T --> A(["entrySet"]):::lp
T --> B(["keySet"]):::lp
T --> C(["forEach"]):::lp
T --> |"流操作"|D(["StreamApi.forEach"]):::lp
T -.-> E(["values"])
A -.-> a("(1)entrySet")
A -.-> a2("(2)entrySet + 迭代器")
B -.-> |"(效率低)"| b("(3)keySet + get()")
C -.-> c("(4)forEach + Lambda")
D -.-> d("(5)Stream().forEach(单线程)")
D -.-> d2("(6)Stream().forEach(多线程)")
E -.-> e("(7)仅遍历value")
classDef p fill:#ddaebd
classDef lp fill:#f4e4e9
classDef B fill:#d9dfeb, stroke:#657eae,stroke-width:2px
遍历HashMap代码:
package com.equne;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class Main {
/** (1)entrySet */
public static void traverse1(Map<String, String> map) {
for (Map.Entry<String, String> entry : map.entrySet()){
System.out.println(entry.getKey() + ", " + entry.getValue());
}
}
/** (2)迭代器(entrySet) */
public static void traverse2(Map<String, String> map) {
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<String, String> entry = iterator.next();
System.out.println(entry.getKey() + ", " + entry.getValue());
}
}
/** (3)keySet + get() */
public static void traverse3(Map<String, String> map) {
for (String key : map.keySet()){
System.out.println(key + ", " + map.get(key));
}
}
/** (4)forEach + Lambda */
public static void traverse4(Map<String, String> map) {
map.forEach((key, value) -> {
System.out.println(key + ", " + value);
});
}
/** (5)StreamApi(单线程) */
public static void traverse5(Map<String, String> map) {
map.entrySet().stream().forEach((entry) -> {
System.out.println(entry.getKey() + ", " +entry.getValue());
});
}
/** (6)StreamApi(多线程) */
public static void traverse6(Map<String, String> map) {
map.entrySet().stream().parallel().forEach((entry) -> {
System.out.println(entry.getKey() + ", " +entry.getValue());
});
}
/** (7)仅遍历value */
public static void traverse7(Map<String, String> map) {
for (String v : map.values()){
System.out.println(v);
}
}
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("key1", "value1");
map.put("key2", "value2");
traverse1(map);
traverse2(map);
traverse3(map);
traverse4(map);
traverse5(map);
traverse6(map);
traverse7(map);
}
}entrySet 和 keySet
- Map.entrySet 迭代器会生成 EntryIterator,其返回的实例是一个包含 key/value 键值对的对象。
- 而 keySet 中迭代器返回的只是 key 对象,还需要到 map 中二次取值(多一个get方法的调用)。故 entrySet 要比 keySet 快一倍左右。(keySet适合仅需要操作key时使用)
🔗 摘自:《Java修炼指南:高频源码解析》
foreach + Lambda 表达式(Java8 的新特性)
- forEach():用于遍历动态数组中每一个元素并执行特定操作。
- Lambda 表达式:箭头符号
->,其两边连接着输入参数和函数体。
Stream()
- 其实用Iterable本身的forEach方法即可,没有必要用流式操作。StreamApi适合在对集合进行其他流式操作之后使用。
- 补充:用流获取映射值的极端案例:🔗 摘自:《好代码,坏代码》
Optional<String> value = map
.entrySet()
.stream()
.filter(entry -> entry.getKey().equals(key))
.map(Entry::getValue) // 双冒号:引用方法
.findFirst();
- end -
参考:
- HashMap扩容部分:《Java高并发与集合框架:JCF和JUC源码分析与实现》
- 内存结构示意图部分:《Java编程的逻辑》